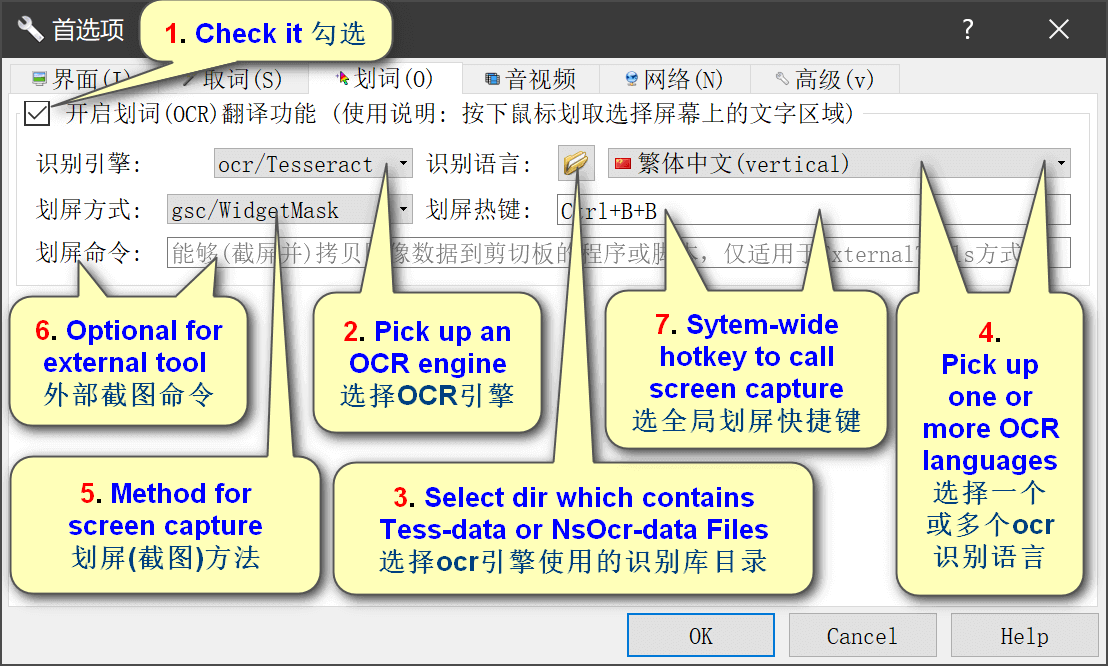
GoldenDict++ OCR · 划词设置


For full OCR support, extra language-packs of ocr-engine are needed and the data-path which is used by ocr-engine for loading language data should be reset to your language-pack dir — download and unpack the following package, open GoldenDIct’s Preference dialog and swich to OCR Popup, select an OCR-Engine and set the data path by clicking the button next to the Engines’ List, then select module language(s) for the engine 「如需OCR支持其它语言,请下载下列OCR支持库,解压后到首选项对话框的划词页,针对OCR引擎重设其识别库目录后选择需要识别的语言。从GD++3E2E版本开始,应用发布包中将不再包含划词OCR所需要的全量模型,您需要下载通用的和针对特定平台的GoldenDict++3E2E-OCR-Model-Files-*模型压缩包,最简单的部署方式是将模型压缩包解压并合并到GD++的运行目录中去,或在运行前在划词设置中指定识别引擎的数据目录」
- OCR Generic Package「公共模型包」: onnx+ncnn+tess or from GitHub
- OCR Windows: Windows_only or from GitHub
- OCR Linux: Linux_only or from GitHub
- Nicomsoft OCR: v70 build885 x64 / x86 or v71 build921 Full Package Installer for Windows, and v70 build885 Full Package for Linux.
- Google Tessdata Fast (273 MB), or others from the Official.
OCR and ScreenCapture Plugins
划词插件插件存放在运行目录下的gdp文件夹内(名称以gdp.gsc和gdp.ocr开始的文件),ncnn引擎使用的默认数据存放在运行目录下的ncnn-ocr文件夹内,onnx引擎使用的默认数据存放在运行目录下的onnx-ocr文件夹内,Tesseract引擎使用的默认数据存放在运行目录下的tessdata文件夹内,Nicomsoft引擎使用的默认数据存放在运行目录下的nsocr文件夹内,划词引擎及数据按需加载但非GoldenDict++版运行的必需组件 — 在不启用划词时程序并不加载划词相关的功能模块(也即不会多占内存和其它硬件资源)。
| Name | File Name | Platform | Ratings | Remarks |
|---|---|---|---|---|
| MacVision | gdp.ocr.macvision.* | macOS ≥10.15 | ***** | Apple’s Vision framework, preferred and recommended on macOS Big Sur or Monterey |
| OneOCR | gdp.ocr.msoneocr.* | Windows x64 ≥10 | ***** | Windows Snipping Tool, preferred and recommended on Windows |
| WinRT | gdp.ocr.winrtocr.* | Windows ≥8 | ***** | Windows.Media.Ocr, preferred and recommended on Windows |
| PP-OCRv5 ONNX | gdp.ocr.ppocr5onnx.* | All | ***** | Awesome multilingual OCR toolkits based on PP-OCRv5(飞桨) and ONNX Runtime |
| Paddle | gdp.ocr.paddle.* | All | **** | PaddleOCR: Awesome multilingual OCR toolkits based on PaddlePaddle(飞桨) |
| PP-OCRv5 NCNN | gdp.ocr.ppocr5ncnn.* | All | **** | Awesome multilingual OCR toolkits based on PP-OCRv5(飞桨) and ncnn |
| PixPin NCNN | gdp.ocr.pixpin.* | All | **** | Chinese OCR based on PixPin-OCR and ncnn |
| Tesseract | gdp.ocr.tesseract.* | All | ***** | With the power of Tesseract, hundreds of languages are supported. Preferred and recommended |
| gdp.ocr.wechatocr.* | Windows/Linux x64 | ***** | 微信文字识别 Automatically installed with WeChat x64 | |
| TextIn | gdp.ocr.textin.* | All | ***** | 合合 TextIn 智能文字识别 textin.com/document/display_type_2 |
| XfYun | gdp.ocr.xfyun.* | All | ***** | 科大讯飞文字识别 xfyun.cn/doc/words/universal_character_recognition |
| Youdao | gdp.ocr.youdao.* | All | ***** | 有道智云通用文字识别 ai.youdao.com/DOCSIRMA/html/ocr |
| Baidu | gdp.ocr.baidu.* | All | ***** | 百度大脑通用文字识别 ai.baidu.com/ai-doc/OCR |
| Tencent | gdp.ocr.tencent.* | All | ***** | 腾讯云文字识别 cloud.tencent.com/document/product/866 |
| gdp.ocr.google.* | All | *** | NOT Tested;developers.google.cn/codelabs | |
| Nicomsoft | gdp.ocr.nicomsoft.* | Windows | *** | Nicomsoft OCR is no longer officially maintained or updated |
| WidgetMask | gdp.gsc.winmask.* | Windows/Linux | ***** | Perfect graber supports taking dynamic shot on multi-screens. Preferred on Windows and Linux |
| ExternalTools | gdp.gsc.fromcliboard.* | All | ***** | Screen graber using external tools. Preferred on macOS and Linux |
| QCamera | gdp.gsc.qtcamera.* | All | *** | Camera image capture using QCamera. |
云(TextIn合合|XfYun科大讯飞|Youdao有道智云|Tencent腾讯云|Baidu百度云)OCR
需要连接到互联网才能使用云OCR功能,且在使用前需要先在各云平台申请OCR接口参数(应用ID和访问密钥等)并填写到对应的\*OCR.api文件中去。
注意:使用这些OCR接口可能需要向云厂商预付或后付费用,计量单位为调用接口次数。划词属于单次少量文字识别场景,所以请酌情使用!
Apple’s Vision OCR
引擎支持的语言由Apple公司新版本的macOS或iOS系统附带(自带,无需额外安装):

oneOCR / Windows Snipping Tool
引擎支持的语言由oneocr.onemodel提供,运行需要先安装Windows Snipping Tool应用,或从应用安装包中提取oneocr.dll、oneocr.onemodel和onnxruntime.dll三个运行时所需文件。
WinRT OCR / Windows.Media.Ocr
引擎支持的语言由Windows系统提供,可在系统的设置项中安装额外的支持语言:


Tesseract OCR
By default GD++ comes packaged with the following languages: English, Chinese Simplified, and Chinese-Traditional (GD++发行包中默认携带了英文、简体中文和繁体中文的tessdata数据包).
Follow these steps if you would like to install additional OCR languages (参考以下步骤安装额外的语言数据包):
- Download the appropriate OCR language dictionary (下载您需要的识别语言的数据包).
- Open the “.zip” file you just downloaded with 7-Zip or similar decompression software (用解压缩软件打开已下载的压缩包).
- Drag all files contained within the zip file to the tessdata folder (从解压缩软件的文件列表中拖拽所有的文件到
GD++部署目录下的tessdata文件夹内):- Re-select module language(s) for the engine (在
GD++中重新为该引擎配置识别语言).
The following OCR languages are supported(全量tessdata数据包支持的语言):
Chinese Simplified Chinese-Simplified (vertical) Chinese-Traditional Afrikaans Irish Norwegian Amharic Galician Occitan(post1500) Arabic Greek, Ancient(to1453) Oriya Assamese Gujarati Panjabi;Punjabi Azerbaijani Haitian; HaitianCreole Polish Azerbaijani-Cyrilic Hebrew Portuguese Belarusian Hindi Pushto;Pashto Bengali Croatian Quechua Tibetan Hungarian Romanian; Moldavian; Moldovan Bosnian Armenian Russian Breton Inuktitut Sanskrit Bulgarian Indonesian Sinhala;Sinhalese Catalan;Valencian Icelandic Slovak Cebuano Italian Slovak-Fraktur Czech Italian-Old Slovenian Javanese Sindhi Japanese(vertical) Spanish; Castilian Japanese Spanish; Castilian-Old Chinese-Traditional (vertical) Kannada Albanian Cherokee Georgian Serbian Corsican Georgian-Old Serbian-Latin Welsh Kazakh Sundanese Danish CentralKhmer Swahili Danish-Fraktur Kirghiz; Kyrgyz Swedish German Kurmanji (Kurdish-LatinScript) Syriac German-Fraktur Korean Tamil Dhivehi; Divehi; Maldivian Korean(vertical) Tatar Dzongkha Kurdish(ArabicScript) Telugu Greek, Modern(1453-) Kurdish(ArabicScript) Tajik English Lao Tagalog English, Middle(1100-1500) Latin Thai Esperanto Latvian Tigrinya Mathandequations Lithuanian Tonga Estonian Luxembourgish Turkish Basque Malayalam Uighur;Uyghur Faroese Marathi Ukrainian Persian Macedonian Urdu Filipino;Pilipino Maltese Uzbek Finnish Mongolian Uzbek-Cyrilic French Maori Vietnamese German-Fraktur Malay Yiddish French, Middle(ca.1400-1600) Burmese Yoruba WesternFrisian Nepali Dutch;Flemish ScottishGaelic;Gaelic
Nicomsoft OCR
该引擎预设的配置参数存在于nsocr目录下的Config.dat文件中,可使用文本编辑器修改,参数信息请参考官方faq和help文档。
Chinese Simplified Chinese Traditional English Estonian Bulgarian Hungarian Slovak Finnish Catalan Indonesian Slovenian French Croatian Italian Spanish German Czech Latvian Swedish Romanian Danish Lithuanian Turkish Russian Dutch Norwegian Arabic Japanese Polish Portuguese Korean
进阶
参考GoldenDict++插件接口定义一文可以开发自己的划屏和OCR引擎。